

Prefer Natural Language? The Meta Agent lets you query the Context Graph conversationally without writing Cypher. Use this Queries page for advanced analysis, custom reporting, or programmatic access via SDK/API.
Prerequisites
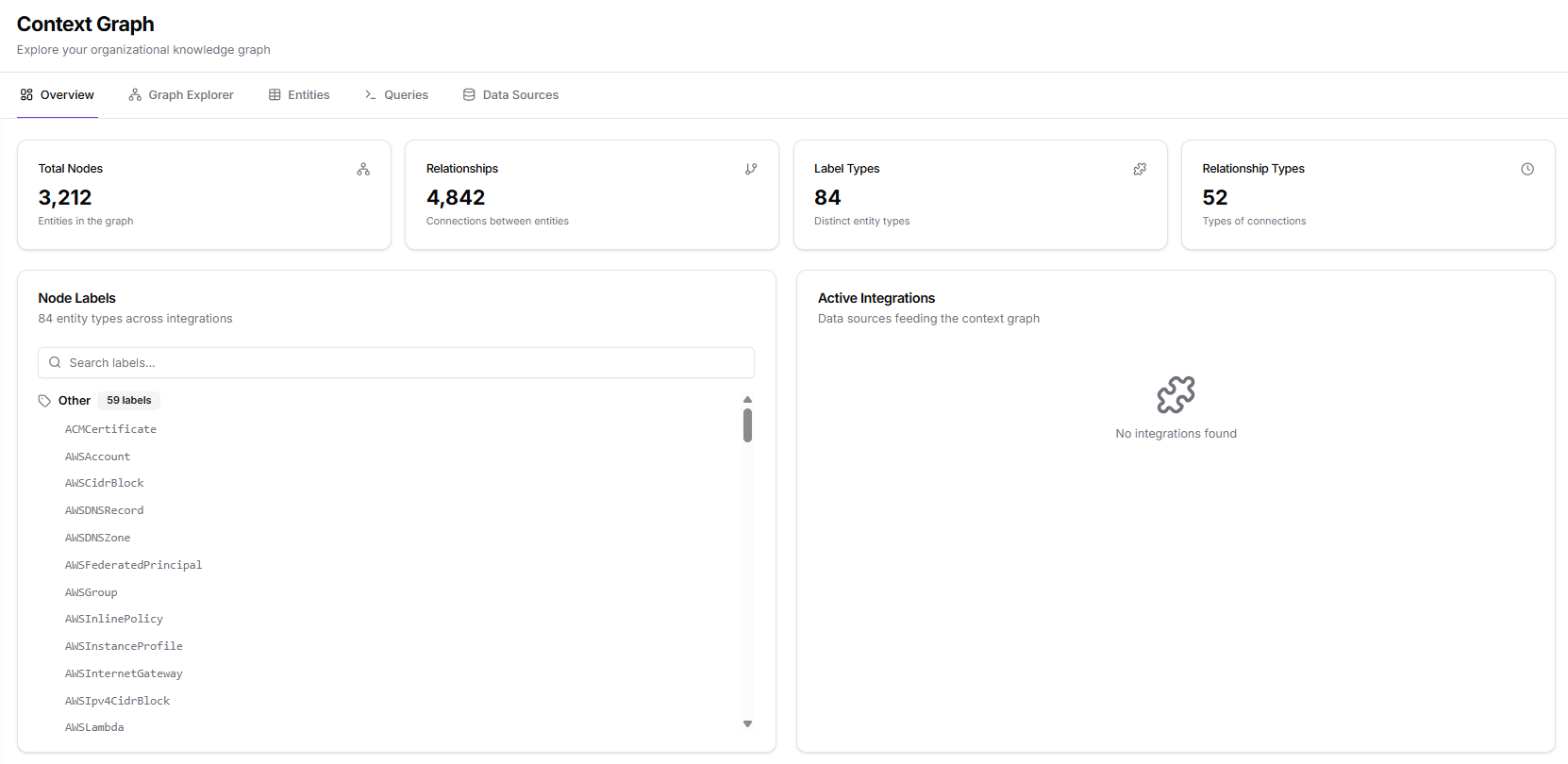
To use Queries effectively:- The Context Graph must contain ingested nodes and relationships
- You should have some familiarity with Cypher syntax
- Ingested data should be up to date to ensure accurate query results
Page Layout and Components
The Queries page is divided into four major areas:- Query Editor: write, modify, and execute Cypher queries
- Query History: access previously executed queries
- Example Queries: curated examples optimized for the backend
- Results Panel: view, expand, and export query results
Query Editor
- A multiline editor for typing queries
- A keyboard shortcut to run queries (Cmd/Ctrl + Enter)
- An Execute button
- Icons for opening query history and example queries
- A button to clear the editor
Query History
- A full list of past queries
- Re-run capability by clicking a past entry
- Clear option to remove history
Example Queries
Below the editor is a collapsible Example Queries section.Get all nodes
Retrieves nodes with full label visibility.Get nodes with properties
Returns nodes that have non-nullname or id.
Find nodes with relationships
Shows nodes together with their relationship details.Count relationships by type
Useful for relationship statistics.Find nodes by property
Query nodes by a property such astype.
Search by property value
Search nodes by name or any other indexed field.Executing Queries
- Press Execute
- Or use Cmd/Ctrl + Enter
- The query appears in Query History
- The results populate instantly in the Results Panel
- Errors (syntax or backend) are returned inline
Results Panel
The right side of the page displays query results. Results appear in a scrollable list with each row formatted as a JSON-like object. Rows expand into full JSON when stretched vertically or interacted with. Key features include:Rows Count
Displayed above results (e.g., 20 rows).Per-row JSON Viewer
Each row is rendered as a structured object that:- Shows all node properties
- Includes nested fields
- Respects full ingestion structure
On-demand formatting
Clicking a row expands the JSON for easier inspection.Export Controls
Two export options are available:- CSV
- JSON
How Queries Help
This page is essential when you need:- Precise graph analysis that goes beyond visual exploration
- Custom queries for reporting or audits
- Fast filtering across thousands of nodes
- Relationship inspection across multiple labels
- Aggregation, grouping, or statistical summaries
- Repeatable analysis using saved or historical queries
What’s Next
Once you are comfortable querying the graph, the next section helps you understand the sources powering the graph:- Data Sources View all connected integrations, ingestion counts, and available types, helping you identify where your graph data originates.