

What is a Worker?
Workers are distributed execution engines that:- Poll Task Queues: Listen for workflow and activity tasks from Temporal
- Execute Agent Workflows: Run AI agents with tools and integrations
- Report Health: Send heartbeats to the Control Plane
- Stream Events: Provide real-time execution updates
- Handle Failures: Automatically retry failed tasks with exponential backoff
Quick Start
Start Your First Worker
Deployment Modes
Local Mode
Development and testing with Python virtual environment
Daemon Mode
Production deployment running as background process
Docker Mode
Containerized deployment with isolation
Kubernetes Mode
Scalable multi-replica deployment with auto-scaling
Ephemeral vs Persistent Workers
Kubiya supports two worker lifecycle models to match different use cases:Ephemeral Workers
Perfect for CI/CD pipelines and single-task automation Ephemeral workers are automatically provisioned to execute a single task and then terminate. They’re ideal for:CI/CD Pipelines
Automatically execute deployment tasks in GitHub Actions, GitLab CI, Jenkins without managing infrastructure
Automation Scripts
Run one-off automation tasks triggered by webhooks, cron jobs, or API calls
Development & Testing
Test agent workflows locally without setting up persistent infrastructure
Cost Optimization
Pay only for actual execution time - no idle workers consuming resources
- ✅ Zero Infrastructure Management: No need to pre-provision or maintain workers
- ✅ Automatic Cleanup: Workers and queues are automatically removed after execution
- ✅ Perfect for CI/CD: Integrate directly into pipelines without worker setup
- ✅ Cost-Effective: Only runs when needed, no idle resource costs
- ✅ Isolated Execution: Each task gets a fresh, clean worker environment
Use Ephemeral Workers When:
- Running tasks in CI/CD pipelines
- Executing occasional automation workflows
- Testing and development
- One-off operations that don’t require persistent infrastructure
Persistent Workers
Best for high-frequency tasks and production workloads Persistent workers run continuously, polling for tasks 24/7. They’re ideal for:- High-Frequency Operations: Responding to frequent execution requests with low latency
- Real-Time Monitoring: Continuously processing alerts and monitoring tasks
- Custom Infrastructure: Running on your specific infrastructure with custom network access
- Stateful Workflows: Maintaining connection pools, caches, and long-running processes
- ✅ Low Latency: Workers are always ready to process tasks immediately
- ✅ Run Anywhere: Deploy on your own infrastructure (local, cloud, on-prem)
- ✅ Custom Configuration: Full control over resources, network, and dependencies
- ✅ Connection Pooling: Maintain persistent connections to databases and services
Comparison
Worker Architecture
Core Components
Communication Flow
- Registration: Worker registers with Control Plane and receives configuration
- Temporal Connection: Connects to Temporal Cloud using provided credentials
- Task Polling: Continuously polls assigned queue for new tasks
- Task Execution: Executes agent workflows and activities
- Event Streaming: Sends real-time events to Control Plane
- Health Reporting: Periodic heartbeats with metrics and status
Deployment Modes
Local Mode
Best for development and testing.- Automatic Python virtual environment setup
- Foreground process with live logging
- Quick iteration and debugging
- Dependencies auto-installed
Daemon Mode
Production deployment as a background process.- Runs in background
- Automatic restart on crash
- Log rotation (configurable)
- PID and status tracking
Docker Mode
Isolated containerized deployment.Kubernetes Mode
Scalable production deployment with high availability.- Basic Deployment
- With Autoscaling
- With Monitoring
Configuration
Environment Variables
string
required
API authentication key for Control Plane
string
default:"https://control-plane.kubiya.ai"
Control Plane base URL
string
Override Control Plane URL (takes precedence)
string
required
Worker queue identifier (must match queue in Control Plane)
string
default:"default"
Environment name for the worker
string
default:"auto-detected"
Custom worker hostname for identification
integer
default:"30"
Heartbeat interval in seconds (15-300)
string
default:"INFO"
Logging level: DEBUG, INFO, WARN, ERROR
integer
default:"10"
Maximum concurrent activity executions
integer
default:"5"
Maximum concurrent workflow executions
string
Explicit model ID to override agent/team configuration. All LLM requests will use this model regardless of agent settings.
Advanced Configuration
Monitoring
Log Management
Health Checks
Metrics
Workers report the following metrics:- Task Execution: Success/failure counts, execution time
- Resource Usage: CPU, memory, network
- Queue Status: Pending tasks, poll rate
- Health Status: Heartbeat success, connectivity
Troubleshooting
Worker Won’t Start
Connection Issues
Worker Crashes
Task Execution Failures
Best Practices
Production Deployment
Use Daemon or Kubernetes Mode: Never run production workers in foreground
Monitor Health: Set up alerting for heartbeat failures
Resource Limits: Configure appropriate CPU/memory limits
Log Rotation: Enable log rotation to prevent disk fill
Multiple Replicas: Run at least 2-3 workers for high availability
Security
- ✅ Store API keys in secrets (Kubernetes Secrets, AWS Secrets Manager)
- ✅ Rotate keys regularly (at least quarterly)
- ✅ Use network policies to restrict traffic
- ✅ Enable TLS for all communications
- ✅ Monitor access logs for suspicious activity
Performance Optimization
Scaling Strategy
- Vertical Scaling
- Horizontal Scaling
- Multi-Queue
Custom LLM Gateway
Workers normally use the Control Plane’s LLM gateway. You can override this to route requests through your own providers (AWS Bedrock, Azure OpenAI, Ollama, etc.) for cost control, observability, or network isolation. Quick example:Worker Pool Web Interface
When you start a worker, it automatically launches a built-in web interface for monitoring, debugging, and testing executions in real-time.Accessing the WebUI
The WebUI is available athttp://127.0.0.1:8088 by default when starting a worker:
Overview Dashboard
The Overview page displays real-time worker metrics, control plane connection status, and recent activity.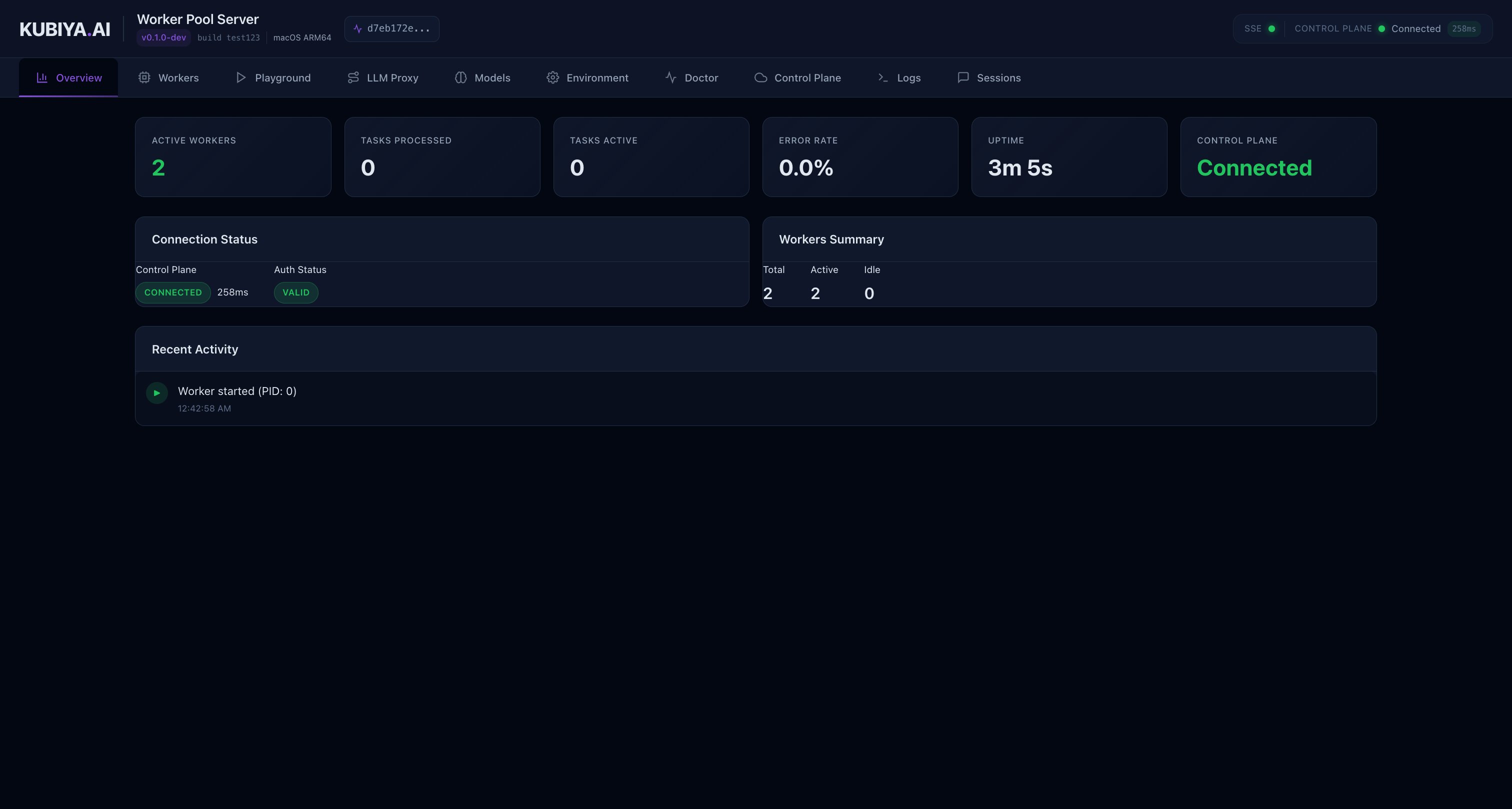
- Worker Status: Active workers, their PIDs, and uptime
- Control Plane Connection: Real-time connection status with latency
- Recent Activity: Latest executions and events
- System Information: Version, build, and OS details
Workers List
Monitor all active workers in your pool with detailed status information.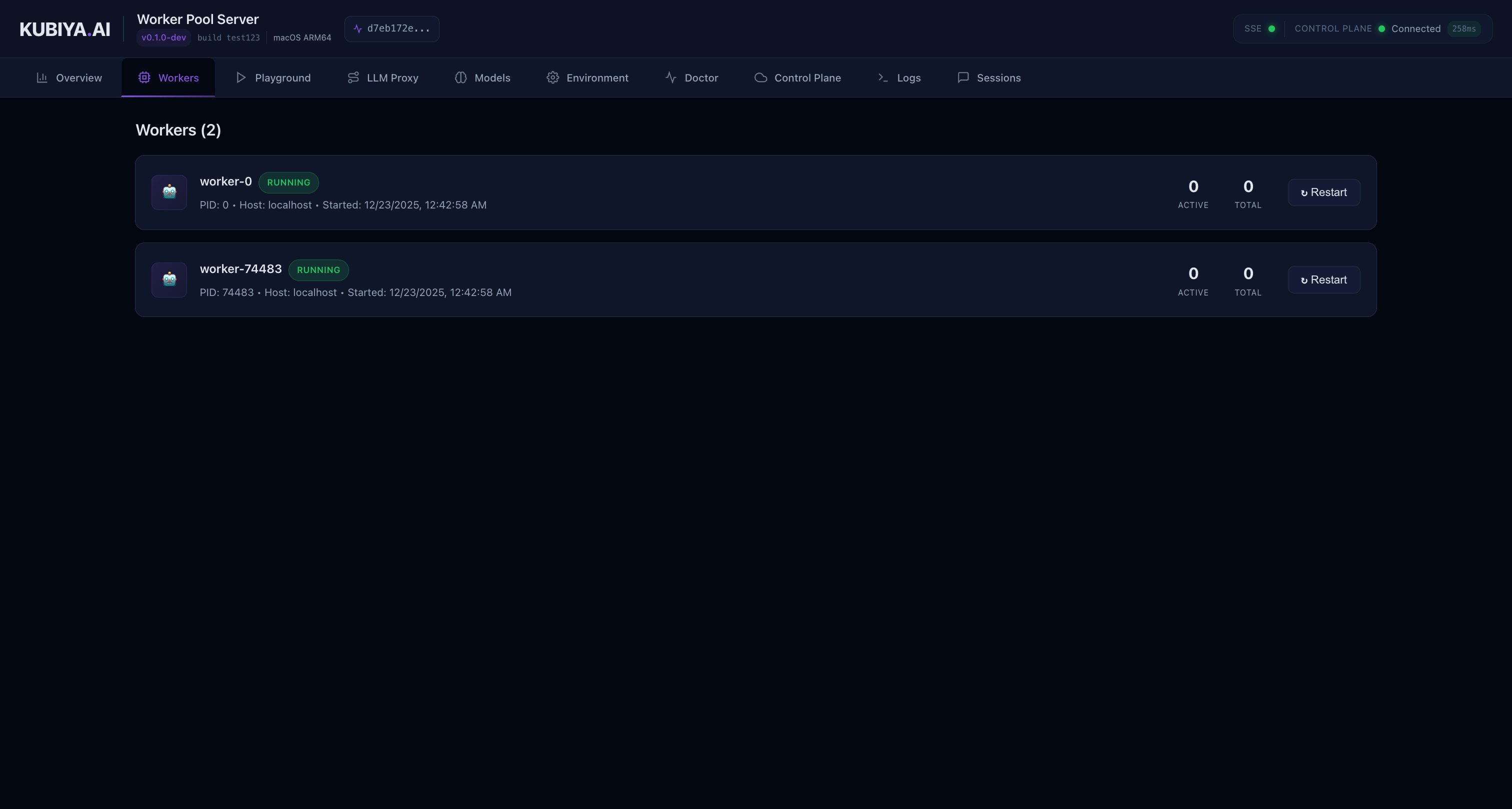
- Worker ID and hostname
- Process ID (PID)
- Current status and uptime
- Task queue assignment
Execution Playground
The Playground provides an interactive interface to test agent executions with real-time streaming output.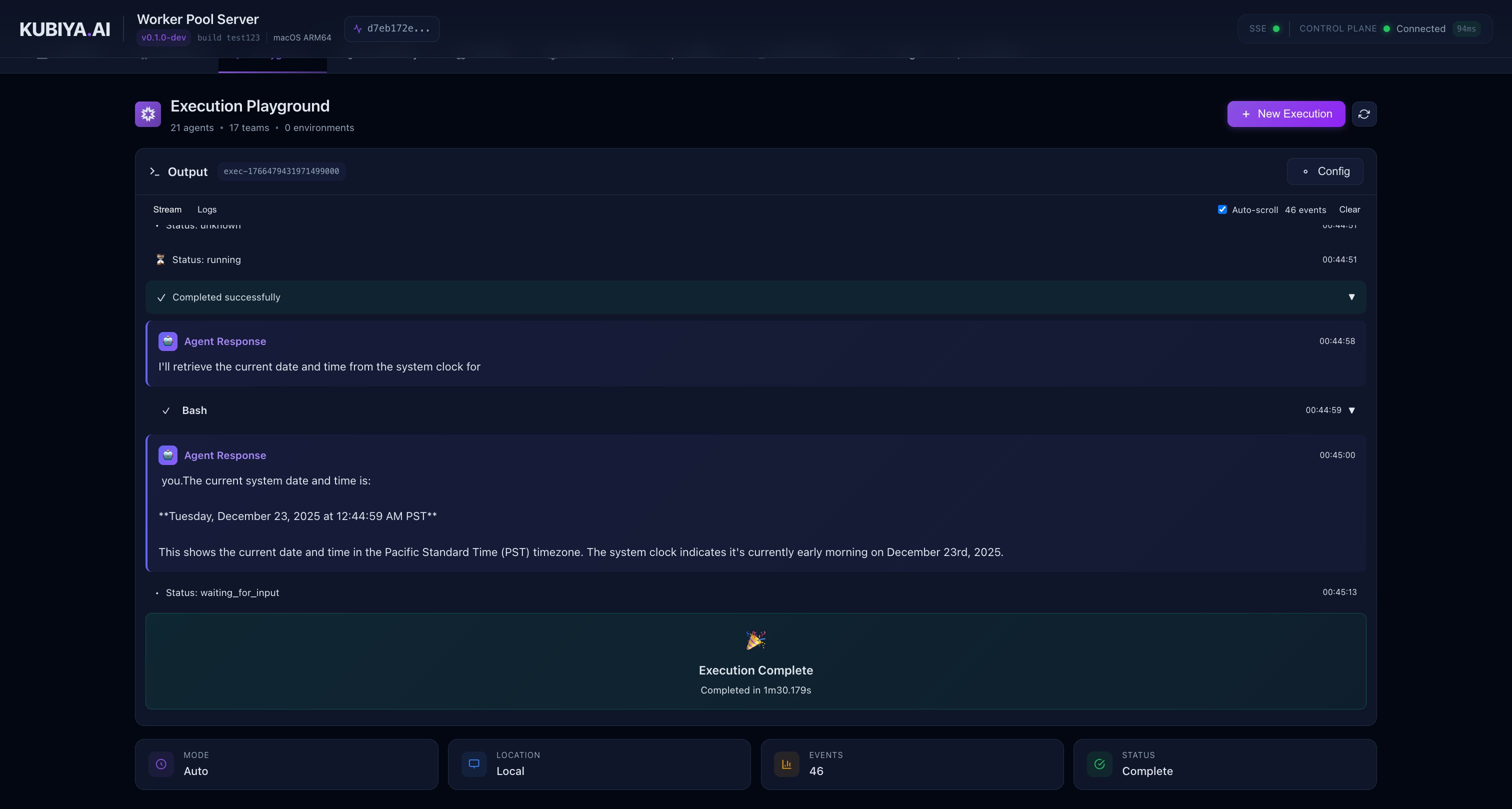
- Agent Selection: Choose from available agents
- Working Directory: Set the execution context
- Real-time Streaming: Watch agent reasoning, tool calls, and outputs live
- Tool Call Visualization: Collapsible cards showing tool inputs and outputs
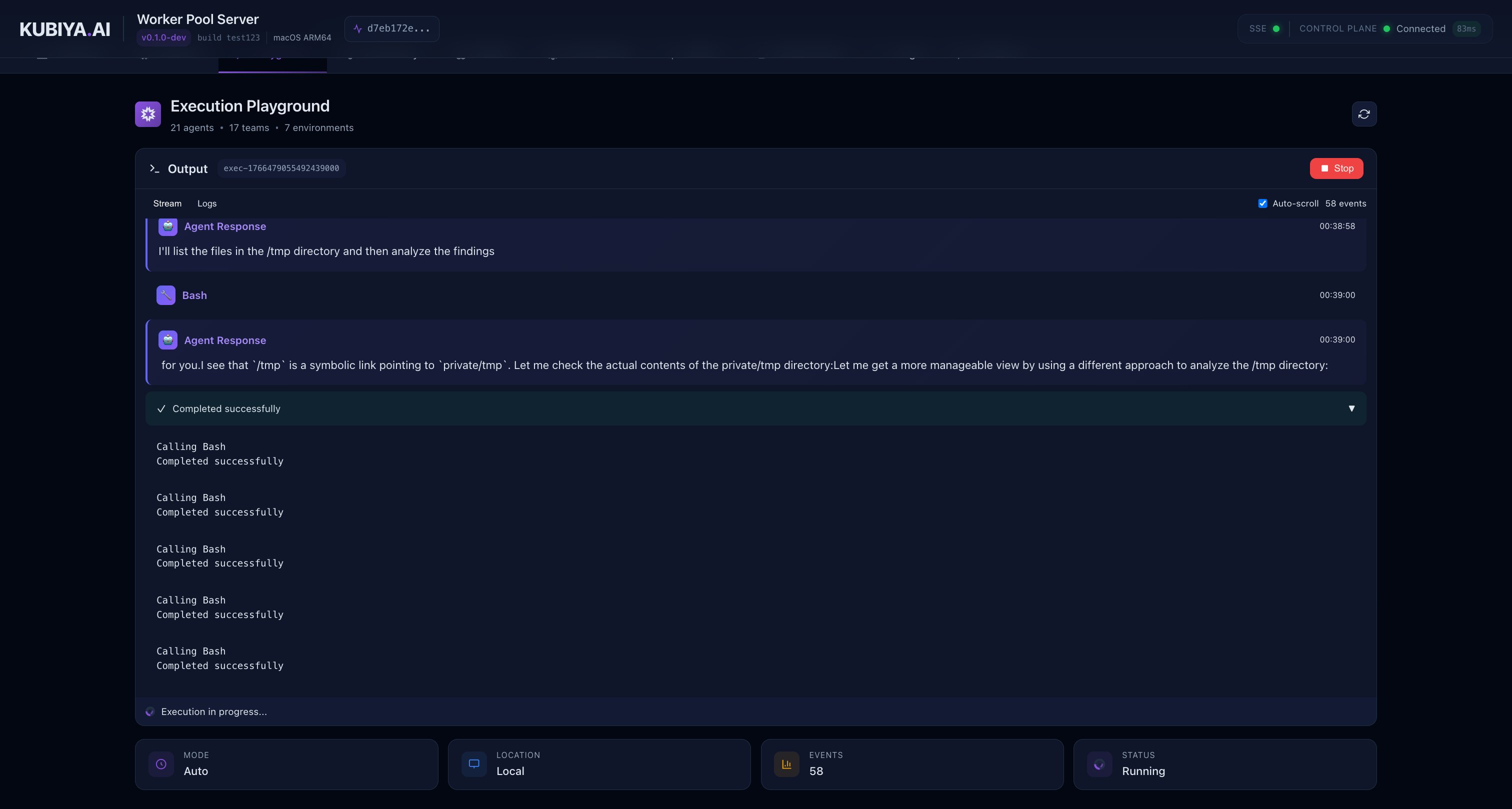
- Agent’s reasoning process
- Tool calls with expandable input/output details
- Real-time output as the agent works
- Execution status and duration
LLM Proxy Control
Manage your local LiteLLM proxy settings when using--enable-local-proxy.
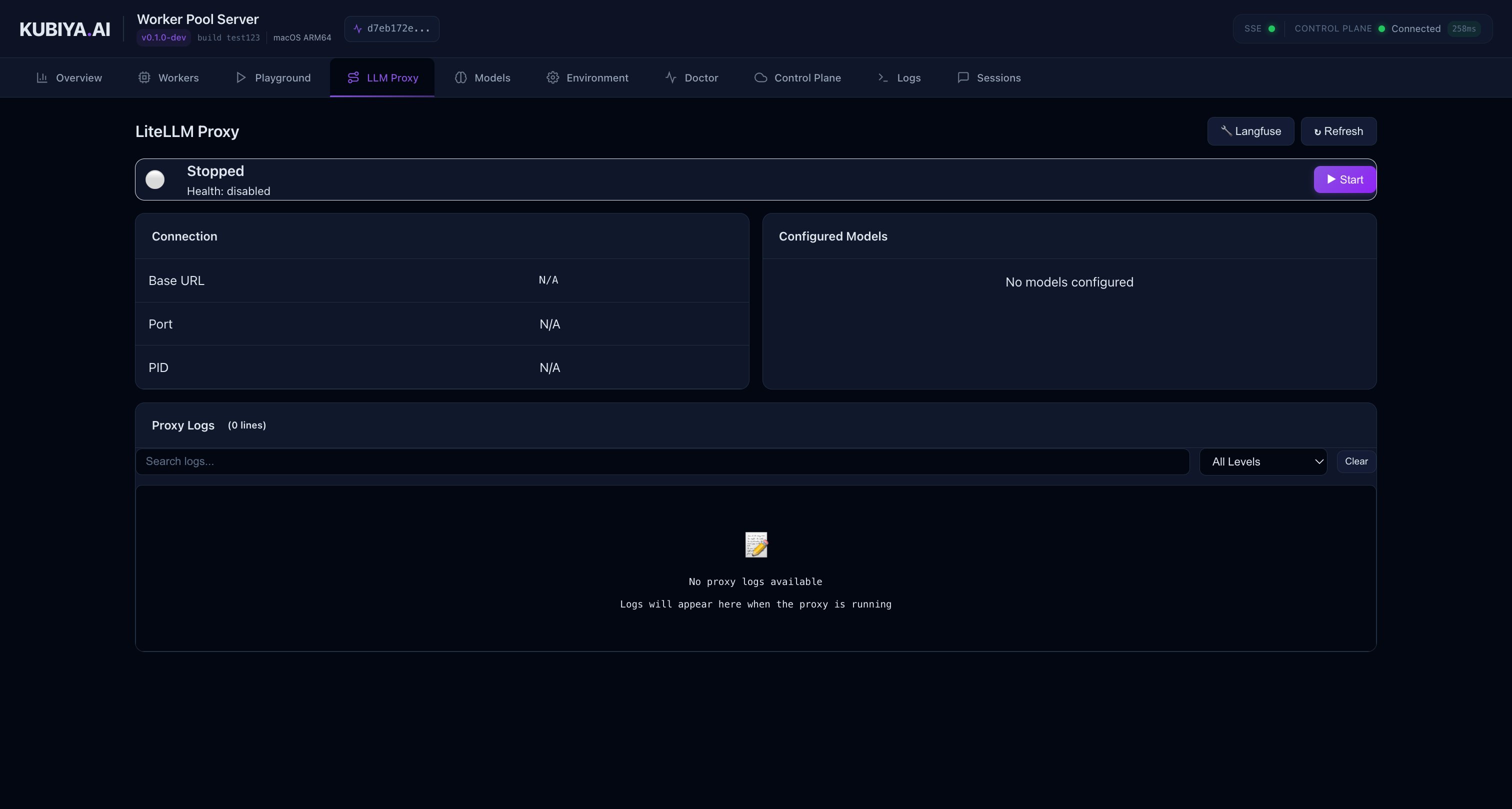
- View proxy status and health
- Monitor request routing
- Check configured model endpoints
Models
Browse and test available LLM models through your configured providers.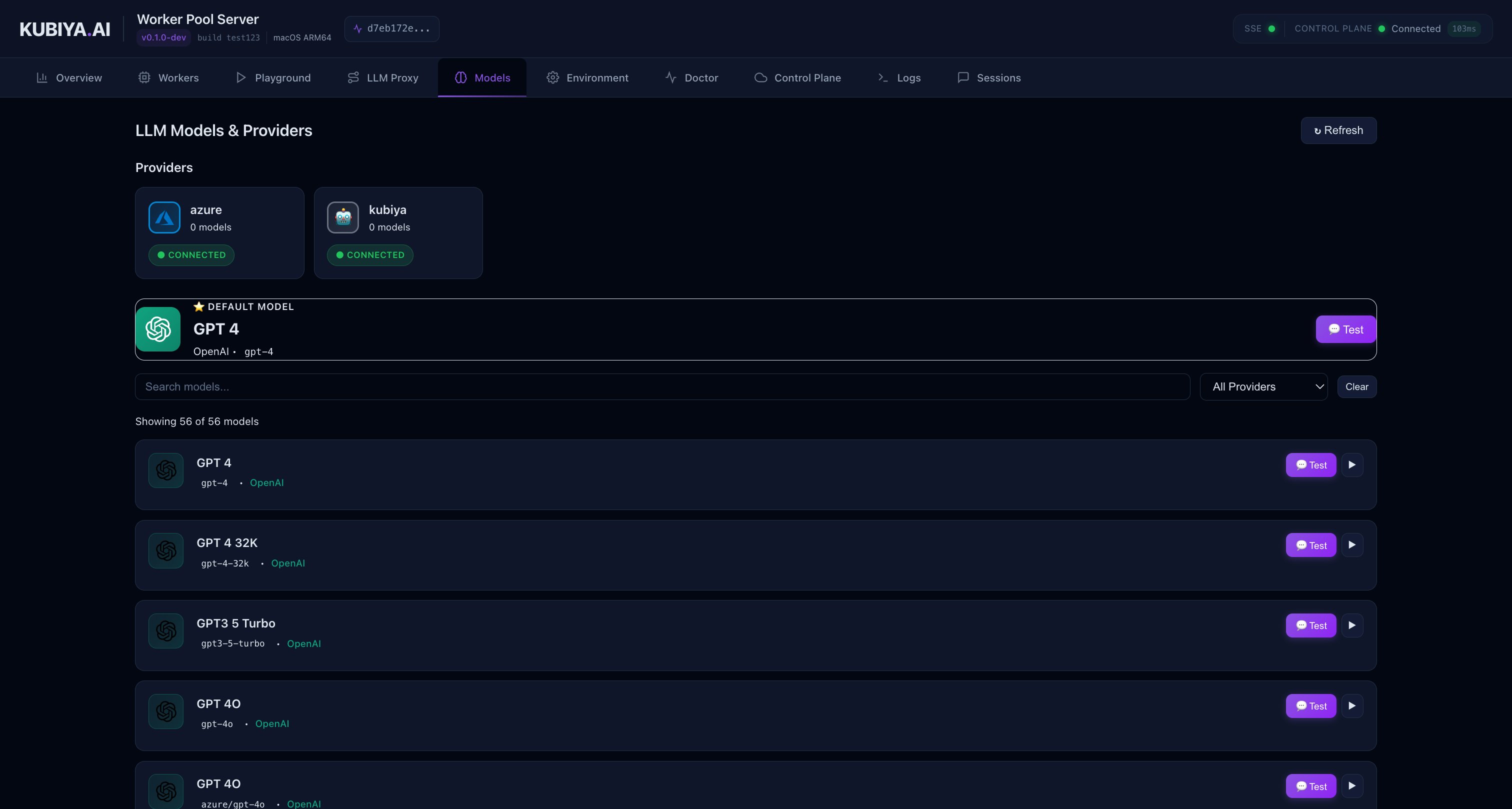
- Available model providers (OpenAI, Anthropic, Bedrock, etc.)
- Model capabilities and pricing tiers
- Quick access to test models in the Playground
Additional Pages
The WebUI includes several other useful pages:- Environment: View and manage environment variables
- Doctor: Diagnostic checks for common configuration issues
- Control Plane: Detailed control plane connection information
- Logs: Real-time log streaming and historical log search
- Sessions: View active and past execution sessions
Command Reference
Worker Start Command
Thekubiya worker start command supports the following flags:
Required Flags
string
required
Worker queue identifier that matches a queue configured in the Control Plane
string
required
Worker deployment type:
local or dockerOptional Flags
boolean
default:"false"
Run worker as background daemon process (shorthand:
-d)integer
default:"104857600"
Maximum log file size in bytes before rotation (daemon mode only)
integer
default:"10"
Number of rotated log files to keep (daemon mode only)
WebUI Flags
integer
default:"8088"
Port for the built-in web interface. The WebUI provides real-time monitoring, execution playground, and diagnostics.
Local LiteLLM Proxy Flags
boolean
default:"false"
Enable local LiteLLM proxy gateway alongside the worker. When enabled, the worker will route all LLM requests through a local proxy instead of the Control Plane gateway.
string
Path to LiteLLM proxy configuration file (JSON or YAML). Requires
--enable-local-proxy.string
Inline LiteLLM proxy configuration as JSON string. Requires
--enable-local-proxy.Model Override Flag
string
Explicit model ID to override agent/team configuration. When set, all LLM requests will use this model regardless of agent settings. Useful for testing, cost control, or debugging. Can also be set via
KUBIYA_MODEL environment variable.Other Worker Commands
Next Steps
Execution Resources
Manage executions and schedule jobs with workers
Smart Execution
Execute tasks with automatic planning
Core Resources
Manage agents and teams
Infrastructure
Deploy operators and manage environments